以下の手順では、AI Playground v2.5.5用にComfyUIをアップデートするために必要な手順を説明します。これにより、Flux.1 Kontext [dev]またはWan 2.1 VACEワークフローをComfyUIから実行できるようになります。
これらのワークフローについて
Flux.1 コンテクスト [dev] Black Forest Labsの画期的な画像編集モデルとワークフローで、画像を編集、スタイル設定、結合することができます。現在、このモデルは開発版としてリリースされており、使用は制限されています。 必ず の条件がある。
See 例

ワン2.1 VACE アリババの高品質ビデオ生成モデルは、ビデオのアクションがどのように生成されるかを高度にコントロールすることができ、生成のコントロールに参照画像と参照ビデオの両方を使用することができます。
See 例

どちらのワークフローも、AI Playgroundがデフォルトでインストールするよりも新しいバージョンのComfyUIを必要とします。これらの指示に従うことで、ComfyUIでこれらの新しいモデルとワークフローを実行することができます。Flux.1 KontextはAI Playgroundで直接実行できます。しかし、これはモデルを手動でインストールする必要があります。 将来のリリースでは、実行に必要なすべてのインストールと生成をAI Playgroundが行うようにする予定です。現在、これらを実行することに興味がある方のために、インストール方法を説明します。 後でAIプレイグラウンドを通してComfyUIを再インストールする必要がある場合、インストールされているモデルとカスタムノードは削除されますのでご注意ください。 ComfyUIのモデルとcustom_nodesフォルダをバックアップすることをお勧めします。
使用方法
ステップ1: ComfyUIをアップデートする:
どちらのワークフローもComfyUIのアップデートが必要です。これは、これらの機能を実行するための最初のステップです。
- ComfyUIなしでAI Playgroundをインストールする
- 基本設定]で[マネージャ・バックエンド・コンポーネント]を選択します。
- ComfyUIの行の右端にある歯車のアイコンを選択し、[設定]を選択します。バージョンを "v0.3.43 "に設定する。
- ComfyUIをインストールするアクションをクリックする
- ワークフローの修正 - この新しいバージョンでは、LTX-Video Image to Videoワークフローに必要な変更があり、LTXVImgToVideoノードに "strength: 1.0 "を追加する必要があります。 ダウンロード この更新されたバージョンを、[インストール場所]/AI Playground/resources/workflowsフォルダに置き、修正する。
- インストール後、AI Playgroundを再起動してください。
- AI Playgroundを起動し、CTRL SHIFT Iでコンソールウィンドウを表示します。
ステップ2a:FLUX.1 コンテクスト
追加パッケージは必要ありません。説明に従ってワークフローを設定し、ComfyUIで実行するだけです。 Intel Core Ultra 200Vでテスト
- AI Playgroundを起動し、CTRL SHIFT Iでコンソールを表示 - すべてのタスクが完了するまで待つ。
- ウェブブラウザでComfyUIをlocalhost:49000で開きます。
- メニューから「新規作成」、「ワークフロー」、「テンプレート参照」、「FLUX」、「FLUX Kontext Dev (Basic)」を選択します。 注 このモデルは、開発および研究目的のみに使用制限されています。
- ワークフローは、不足しているモデルがあることを教えてくれます。すべてのモデルをインストールする
- モデルがダウンロードされたら、以下のように移動させる:
- flux1-dev-kontext_fp8_scaled.safetensorsを[AIプレイグラウンドのインストール場所]/AIプレイグラウンド/リソース/ComfyUI/models/diffusion_models/にコピーする。
- ae.safetensor TO [AI Playgroundのインストール場所]/AI Playground/リソース/ComfyUI/models/vae/へ
- clip_l.safetensors, t5xxl_fp16.safetensors AND t5xxl_fp8_e4m3fn_scaled.
safetensors TO [AI Playgroundのインストール場所]/AI Playground/リソース/ComfyUI/models/text_encoders/へ
- ComfyUIがあるブラウザを更新し、Load Image Nodeを使って編集する参照画像を読み込みます。
- ポジティヴ・プロンプト・クリップ・ノードで、画像がどのように変化するかを描写する、つまりスタイル(アニメ)を描写する、画像の中の何を削除または追加するかを描写する、時間帯が違うかどうかを描写する、画像の中のキャラクターが違うかどうかを描写する、つまりゾンビにする、など。
ワークフローの例 ダウンロードしてComfyUIにドラッグ
-
- 画像の編集/変更 (ダウンロードワークフロー)
- 2つの画像を合成するダウンロードワークフロー)
ステップ2b:AIプレイグラウンドでFLUX.1 Kontextを実行します:
これにより、Flux Kontext画像編集のフロントエンドとしてAI Playgroundを使用できるようになります。ただし、最初にステップ2aを使用してComfyUIにモデルを手動でインストールする必要があります。以下のワークフローjsonを追加すると、AI Playgroundから直接実行できるようになります。
- ダウンロード AIプレイグラウンドのワークフロー(json)AI Playgroundのインストール場所]/AI Playground/resources/workflowsに配置してください。
- AIプレイグラウンドの開始
- 設定」→「イメージ」タブ→「ワークフロー」→「Flux-Kontext1」を選択。
- ステップが20、画像数が1に設定されていることを確認してください。
(私の経験では、コーヒーカップを外したり、口ひげやサングラスを付けたりするような小さな変更は、多くのステップを必要としないかもしれない)。 少ないステップで実験してみてください。私の経験では、小さな変化は4ステップと20ステップで同じように見えます) - 画像フィールドに画像を読み込む
- 作成タブのプロンプトで、写真について変更したい点を記述します。次に
(フラックス・シュネルに比べて生成は遅くなるが、よりコントロールしやすくなり、反復回数が少なくて済む可能性が高い)。
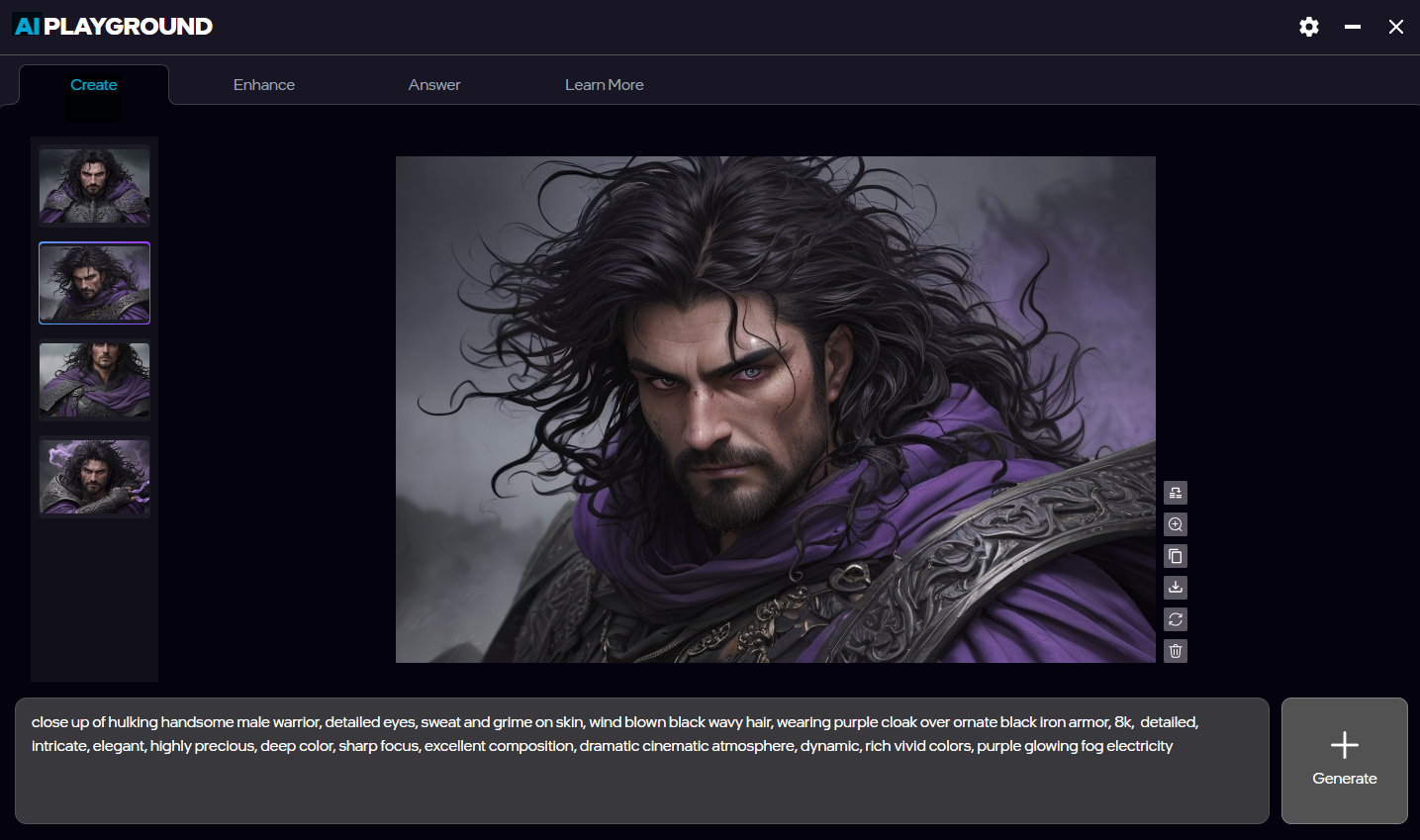
![Screenshot of AI Playground running Flux.1 Kontext [dev] where the prompte "remove the microphone" having edited the image](https://game.intel.com/wp-content/uploads/2025/07/Screenshot-2025-07-09-150445-1-1024x576.png)
ステップ 3 ワン 2.1 VACE
このソリューションには、ComfyUIがアップデートする以外の追加のパッケージとモデルが必要です。このワークフローはIntel Arc A770でテストされました。
クローンGGUFノード (古いGGUFノードは削除して更新する必要があるかもしれません)
- ディレクトリ[AI Playgroundのインストール場所]/AI Playground/resources /ComfyUI/custom_nodesを開きます。
- このウィンドウのタイトルバーに移動し、CMDと入力して、この場所でコマンドウィンドウを起動する。
- CMDウィンドウでそれぞれを実行する: (各行を貼り付けてからリターンを押し、完了するまで待ってから次の行を同じように貼り付ける)。
- git clone https://github.com/city96/ComfyUI-GGUF
- git clone https://github.com/
コシンカディンク/ComfyUI ビデオヘルパースイート - git clone https://github.com/Fannovel16/
comfyui_controlnet_aux
ノードのインストール
- AI Playgroundのインストール場所]/AI Playgroundのディレクトリを開きます。
バックエンド - このウィンドウのタイトルバーに移動し、CMDと入力して、この場所でコマンドウィンドウを起動する。
- CMDウィンドウでそれぞれを実行する: (各行を貼り付けてからリターンを押し、完了するまで待ってから次の行を同じように貼り付ける)。
- python -s -m pip install -r .
ComfyUI-GGUFrequirements.txt - python -s -m pip install -r .
ComfyUI-VideoHelperSuite 要件.txt - python -s -m pip install -r .
comfyui_controlnet_aux 要件.txt
- python -s -m pip install -r .
GGUFモデルをダウンロードする
- ダウンロード Wan2.1 14B VACE-Q8_0.gguf ComfyUI/models/unet に移動する。
- ダウンロード umt5-xxl-encoder-Q4_K_M.gguf ComfyUI/models/text_encoders に移動する。
- ダウンロード Wan21_CausVid_14B_T2V_lora_rank32.safetensors ComfyUI/models//loras に移動します。
- ダウンロード wan_2.1_vae.safetensors ComfyUI/models/vae に移動します。
ワークフローの設定
- AI Playgroundを起動し、CTRL SHIFT Iでコンソールを表示 - すべてのタスクが完了するまで待つ。
- AI Playgroundをもう一度再起動し、CTRL SHIFT Iでコンソールを表示します。
- ブラウザをlocalhost:49000に開く
- これらのワークフローのいずれかをダウンロードし、ComfyUIにドラッグします。
- 画像はLoRAを使ったビデオ(ダウンロードワークフロー)
- コントロール用参考ビデオダウンロードワークフロー)
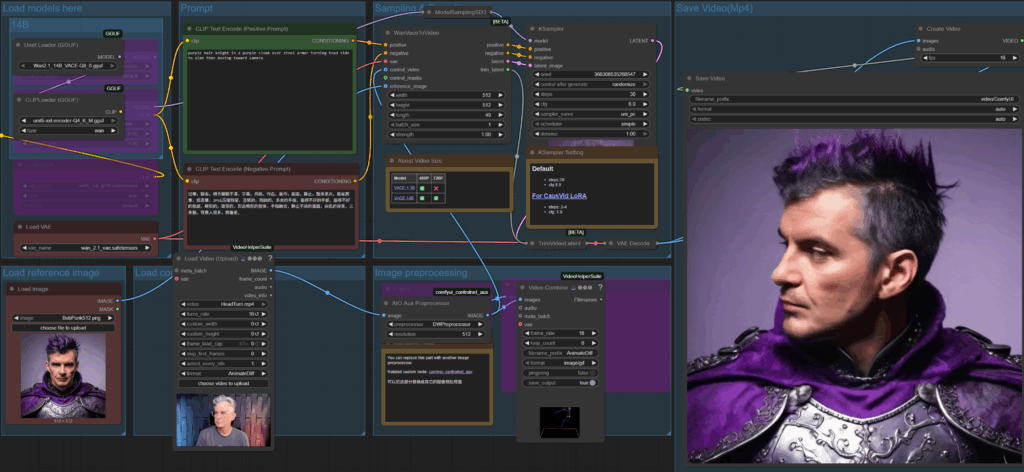
ランニングに関する注意事項
- 以下のノードはオフ/ピンクにします(ノードのオン/オフを切り替えるには、ノードを選択してCTRL Bをタイプします)。
- 3Bノードロード・ディフュージョン、ロード・クリップ、ロード・ローラ
- 14Bノードロードディフュージョン、ロードクリップ
- オプション:14BグループLoRAをオフにすることで、より高画質で、より長時間の生成が可能になる。
- Kサンプラーの設定値
- LoRAがオフの場合、サンプルを20に、CFGを6に設定する。
- LoRAがオンの場合、samplesを4に、CFGを1に設定する。
- 参照画像を追加し(背景は無地がベスト)、Wan Vaceノードの値を解像度に合わせて設定します。フレーム数を設定する。
- ポジティブクリップのプロンプトで何が起こっているかを説明する。
- リファレンスビデオバージョンでは、アクションをガイドするコントロールビデオを追加します。
これで完了だ。我々は、これらのワークフローを今後のリリースに組み込むよう努力し、これらの手順を不要にするつもりだ。その間に、これらのモデルの実験を楽しんでください。また、ご質問やご意見がありましたら、下記までご連絡ください。 http://discord.gg/intel ai-playgroundのスレッドで私とチャットしてください。 X @bobduffy or リンクトイン - ボブ・ダフィー.