What’s better than getting an upgrade in performance? Getting it for free! We have good news to share: As part of our continuous platform optimizations, we are rolling out a power management update that improves gaming performance for Intel® Core™ Ultra 200V systems (codenamed: Lunar Lake) with built-in Intel Arc 140V and 130V GPUs.
This update is delivered through the graphics driver, and its performance benefits are observed primarily at or under the common default power level of 17W.
In testing this update across 9 games on the MSI Claw 8 AI+ in the Manual 17W profile, players can expect higher average GPU frequency and improved frame pacing, which translates to significant uplifts in not only average FPS but also in 1% low FPS, also called the 99th percentile. What this all means is we’re improving not only performance but also smoothness for a great gaming experience.
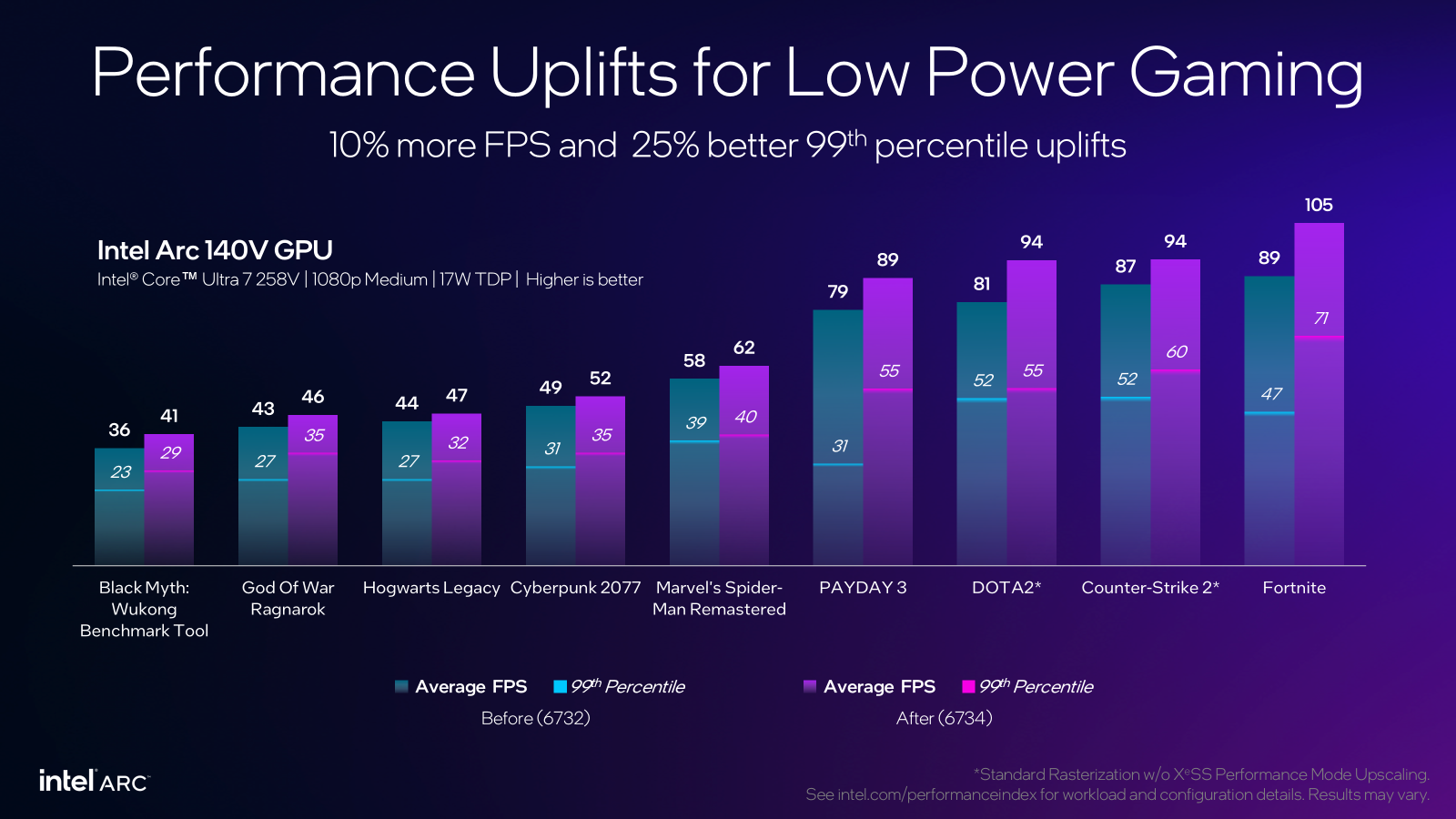
This update is now available for the MSI Claw 8 AI+ and MSI Claw 7 AI+ on Intel graphics driver 32.0.101.6734 and newer, and will be enabled for other Intel Core Ultra 200V systems soon, following validation with our OEM partners. Happy Gaming!