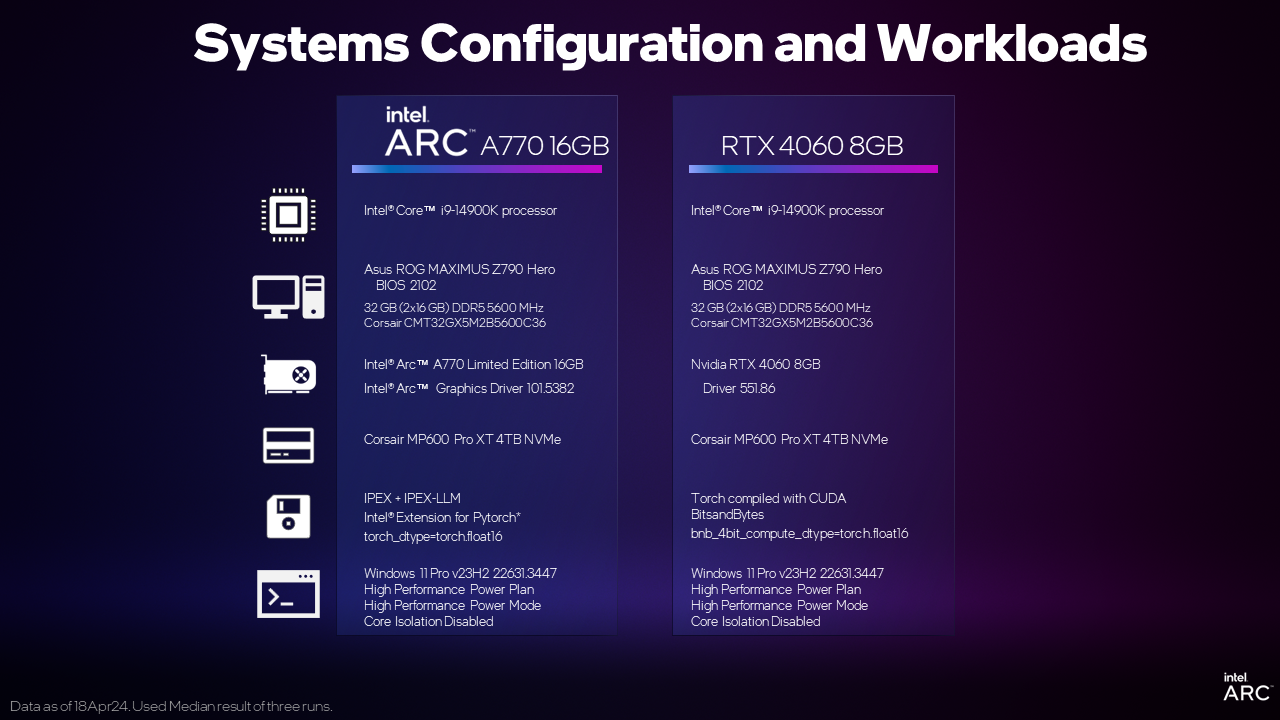
Execute facilmente uma variedade de LLMs localmente com as GPUs Intel® Arc
A IA generativa mudou o cenário do que é possível na criação de conteúdo. Essa tecnologia tem o potencial de fornecer imagens, vídeos e textos nunca antes imaginados. Os modelos de linguagem ampla (LLMs) têm sido manchetes na era da IA, permitindo que qualquer pessoa possa gerar letras de músicas, obter respostas para perguntas complexas sobre física ou elaborar um esboço para uma apresentação de slides. E esses recursos de IA não precisam mais estar conectados à nuvem ou a serviços de assinatura. Eles podem ser executados localmente no seu próprio PC, onde você tem controle total sobre o modelo para personalizar o resultado.
Neste artigo, mostraremos como configurar e experimentar modelos de linguagem grandes (LLMs) populares em um PC com a placa de vídeo Intel® Arc™ A770 de 16 GB. Embora este tutorial faça uso do LLM Mistral-7B-Instruct, essas mesmas etapas podem ser usadas com um LLM PyTorch de sua escolha, como Phi2, Llama2 etc. E sim, com o modelo mais recente do Llama3 também!
IPEX-LLM
A razão pela qual podemos executar uma variedade de modelos usando a mesma instalação básica é graças a IPEX-LLMuma biblioteca LLM para PyTorch. Ela é construída sobre o Extensão Intel® para PyTorch e contém otimizações LLM de última geração e compactação de pesos de bits baixos (INT4/FP4/INT8/FP8) - com todas as otimizações de desempenho mais recentes para o hardware Intel. O IPEX-LLM aproveita as vantagens do Xe-Armazena a aceleração XMX AI em GPUs discretas da Intel, como as placas de vídeo Arc série A, para melhorar o desempenho. Ele oferece suporte aos gráficos Intel Arc série A no Subsistema Windows para Linux versão 2, ambientes Windows nativos e Linux nativo.
E como tudo isso é nativo do PyTorch, você pode trocar facilmente os modelos e os dados de entrada do PyTorch para executá-los em uma GPU Intel Arc com aceleração de alto desempenho. Este experimento não teria sido completo sem uma comparação de desempenho. Usando as instruções abaixo para a Intel Arc e as instruções comumente disponíveis para a concorrência, analisamos duas GPUs discretas posicionadas em um segmento de preço semelhante.
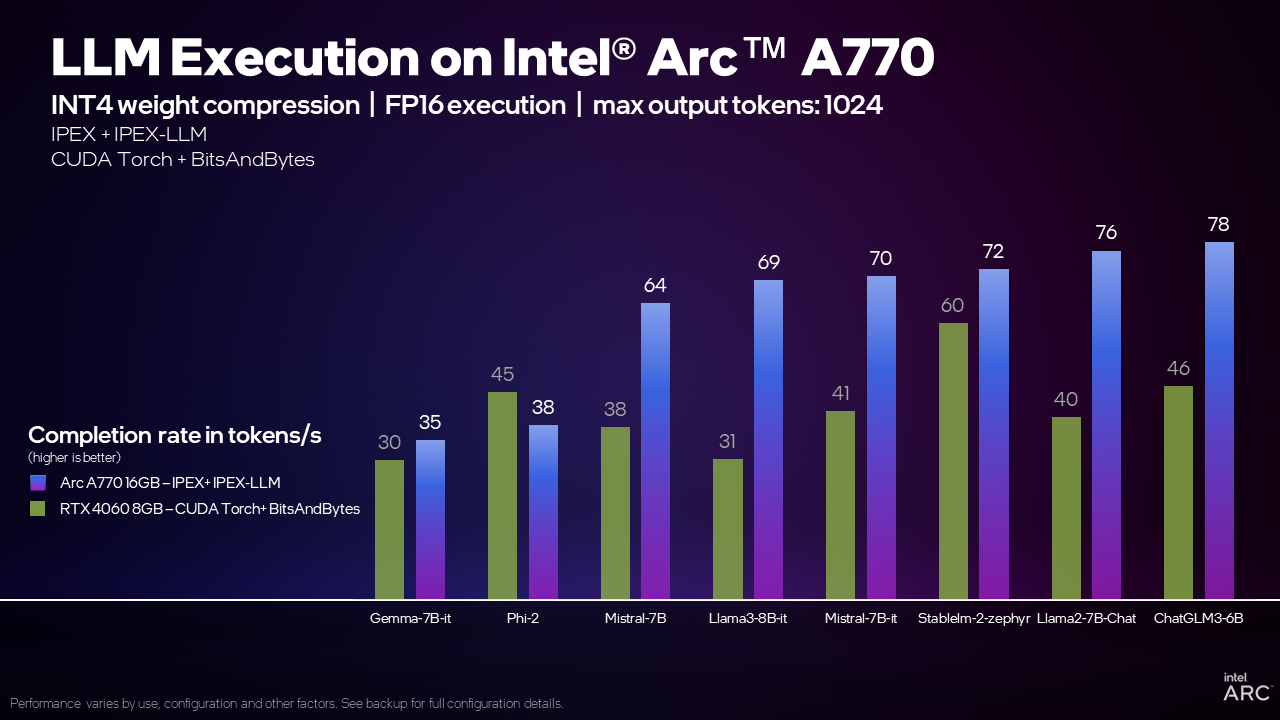
Por exemplo, ao executar o modelo Mistral 7B com a biblioteca IPEX-LLM, a placa de vídeo Arc A770 16GB pode processar 70 tokens por segundo (TPS), ou 70% mais TPS do que a GeForce RTX 4060 8GB usando CUDA. O que isso significa? Uma regra geral é que 1 token é equivalente a 0,75 de uma palavra e uma boa comparação é o velocidade média de leitura humana de 4 palavras por segundo ou 5,3 TPS. A placa de vídeo Arc A770 16GB pode gerar palavras muito mais rapidamente do que uma pessoa comum pode lê-las!
Nossos testes internos mostram que a placa de vídeo Arc A770 de 16 GB pode oferecer esse recurso e um desempenho competitivo ou líder em uma ampla gama de modelos em comparação com a RTX 4060, o que torna a placa de vídeo Intel Arc uma ótima opção para a execução LLM local.
Agora vamos às instruções de configuração para que você comece a usar LLMs na GPU Arc série A.
Instruções de instalação
Também podemos consultar esta página para configurar o ambiente: Instalação do IPEX-LLM no Windows com GPU Intel - Documentação mais recente do IPEX-LLM
1. Desative a GPU integrada no gerenciador de dispositivos.
2. Faça o download e instale Anaconda.
3. Após a conclusão da instalação, abra o menu Iniciar, procure o Anaconda Prompt, execute-o como administrador e crie um ambiente virtual usando os seguintes comandos. Digite cada comando separadamente:
conda create -n llm python=3.10.6
conda activate llm
conda install libuv
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0 gradio
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
pip install transformers==4.38.04. Crie um documento de texto chamado demo.py e salve-o em C:\Users\Your_Username\Documents ou no diretório de sua escolha.
5. Abra o arquivo demo.py com seu editor favorito e copie o seguinte exemplo de código para ele:
from transformers import AutoTokenizer
from ipex_llm.transformers import AutoModelForCausalLM
importar torch
importar intel_extension_for_pytorch
device = "xpu" # o dispositivo para carregar o modelo
model_id = "mistralai/Mistral-7B-Instruct-v0.2" # id do modelo huggingface
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, torch_dtype=torch.float16)
model = model.to(device)
mensagens = [
{"role": "user", "content": "Qual é o seu condimento favorito?"},
{"role": "assistant" (assistente), "content" (conteúdo): "Bem, eu gosto bastante de um bom suco de limão fresco. Ele acrescenta a quantidade certa de sabor picante ao que quer que eu esteja preparando na cozinha!"},
{"role": "user" (usuário), "content" (conteúdo): "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(dispositivo)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decodificado = tokenizer.batch_decode(generated_ids)
print(decoded[0])Código criado a partir do código de amostra neste repositório.
6. Salve o arquivo demo.py. No Anaconda, navegue até o diretório em que o demo.py está localizado usando o comando cd e execute o seguinte comando no prompt do Anaconda:
python demo.pyAgora você pode obter uma boa receita para fazer maionese!
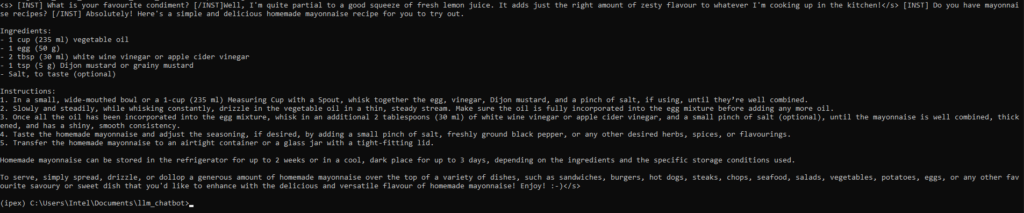
Mudança de modelos
Usando o mesmo ambiente que configuramos acima, você pode experimentar outros modelos populares no Hugging Face, como llama2-7B-chat-hf, llama3-8B-it, phi-2, gemma-7B-i e stablelm2, substituindo o ID do modelo Hugging Face acima no demo.py.
model_id = "mistralai/Mistral-7B-Instruct-v0.2" ID do modelo huggingface #
para
model_id = "stabilityai/stablelm-2-zephyr-1_6b" # id do modelo huggingfaceModelos diferentes podem exigir uma versão diferente do pacote de transformadores. Se você encontrar erros ao iniciar o demo.py, siga as etapas abaixo para fazer upgrade/downgrade dos transformadores:
- Abrir o prompt do Anaconda
- conda activate llm
- pip install transformers==4.37.0
Versões verificadas dos transformadores:
| ID do modelo | Versões do pacote de transformadores |
|---|---|
| meta-llama/Llama-2-7b-chat-hf | 4.37.0 |
| meta-llama/Meta-Llama-3-8B-Instruct | 4.37.0 |
| stabilityai/stablelm-2-zephyr-1_6b | 4.38.0 |
| mistralai/Mistral-7B-Instruct-v0.2 | 4.38.0 |
| microsoft/phi-2 | 4.38.0 |
| google/gemma-7b-it | 4.38.1 |
| THUDM/chatglm3-6b | 4.38.0 |
Os requisitos de memória podem variar de acordo com o modelo e a estrutura. Para o Intel Arc A750 8GB em execução com o IPEX-LLM, recomendamos o uso do Llama-2-7B-chat-hf, Mistral-7B-Instruct-v0.2, phi-2 ou chatglm3-6B.
Implementação de uma WebUI do ChatBot
Agora, vamos implementar um webui do chatbot do Gradio para obter uma experiência melhor usando seu navegador da Web. Para obter mais informações sobre a implementação de um chatbot interativo com LLMs, visite https://www.gradio.app/guides/creating-a-chatbot-fast
1. Crie um documento chamado chatbot_gradio.py no editor de texto de sua preferência.
2. Copie e cole o seguinte trecho de código no chatbot_gradio.py:
importar gradio como gr
importar torch
import intel_extension_for_pytorch
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
model_id = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, optimize_model=True, load_in_4bit=True, torch_dtype=torch.float16)
model = model.half()
model = model.to("xpu")
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [29, 0]
para stop_id em stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
def predict(message, history):
stop = StopOnTokens()
history_format = []
for human, assistant in history:
history_format.append({"role": "user", "content": human })
history_format.append({"role": "assistant", "content":assistant})
history_format.append({"role": "user", "content": message})
prompt = tokenizer.apply_chat_template(history_format, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to("xpu")
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=300,
do_sample=True,
top_p=0,95,
top_k=20,
temperature=0.8,
num_beams=1,
pad_token_id=tokenizer.eos_token_id,
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
partial_message = ""
for new_token in streamer:
if new_token != '<':
partial_message += new_token
yield partial_message
gr.ChatInterface(predict).launch()3. Abra um novo prompt do anaconda e digite os seguintes comandos:
- pip install gradio
- conda activate llm
- cd para o diretório em que o chat_gradio.py está localizado
- python chatbot_gradio.py
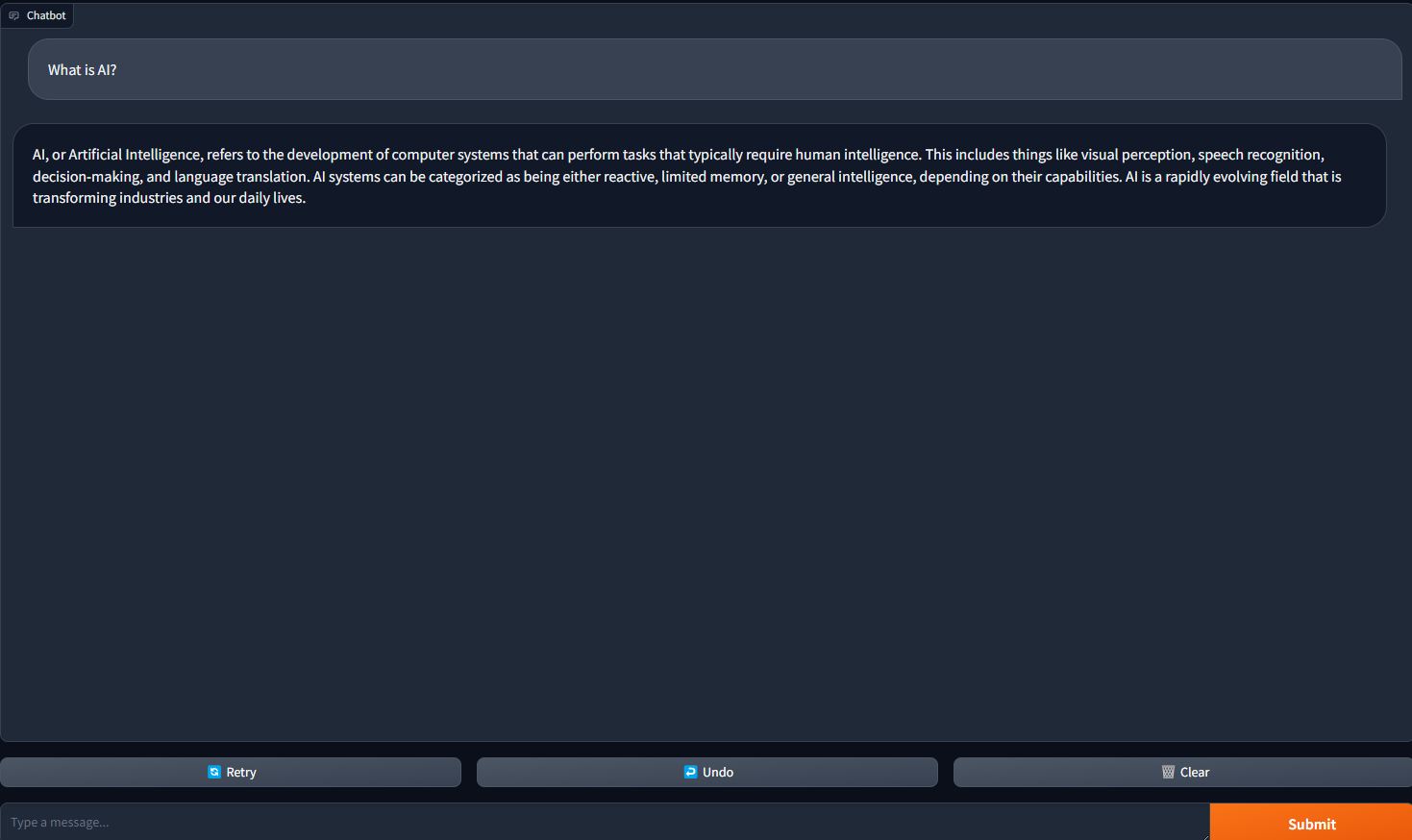
4. Abra seu navegador da Web e navegue até 127.0.0.1:7860. Você verá um chatbot configurado com o modelo de linguagem mistral-7b-instruct-v0.2! Agora você tem um webui de aparência sofisticada para o seu chatbot.
5. Faça uma pergunta para iniciar uma conversa com seu chatbot.
Avisos e isenções de responsabilidade
O desempenho varia de acordo com o uso, a configuração e outros fatores. Saiba mais sobre o Site do Índice de Desempenho.
Os resultados de desempenho são baseados em testes realizados nas datas mostradas nas configurações e podem não refletir todas as atualizações disponíveis publicamente. Consulte o backup para obter detalhes da configuração. Nenhum produto ou componente pode ser absolutamente seguro.
Os resultados que se baseiam em sistemas e componentes de pré-produção, bem como os resultados que foram estimados ou simulados usando uma Plataforma de Referência Intel (um exemplo interno de novo sistema), análise interna da Intel ou simulação ou modelagem de arquitetura são fornecidos apenas para fins informativos. Os resultados podem variar com base em alterações futuras em quaisquer sistemas, componentes, especificações ou configurações.
Seus custos e resultados podem variar.
As tecnologias Intel podem exigir a ativação de hardware, software ou serviço.
© Intel Corporation. Intel, o logotipo da Intel, Arc e outras marcas da Intel são marcas registradas da Intel Corporation ou de suas subsidiárias.
*Outros nomes e marcas podem ser reivindicados como propriedade de terceiros.