Exécuter facilement une variété de LLM localement avec les GPU Intel® Arc™
L'IA générative a changé le paysage de ce qui est possible en matière de création de contenu. Cette technologie a le potentiel de produire des images, des vidéos et des écrits inimaginables jusqu'à présent. Les grands modèles de langage (LLM) ont fait les gros titres à l'ère de l'IA, permettant à quiconque de générer des paroles de chansons, d'obtenir des réponses à des questions de physique complexes ou de rédiger le plan d'une présentation de diapositives. Ces fonctions d'IA n'ont plus besoin d'être connectées au nuage ou à des services d'abonnement. Elles peuvent être exécutées localement sur votre propre PC, où vous avez un contrôle total sur le modèle afin de personnaliser ses résultats.
Dans cet article, nous allons vous montrer comment configurer et expérimenter les grands modèles de langage (LLM) populaires sur un PC équipé de la carte graphique Intel® Arc™ A770 16 Go. Bien que ce tutoriel utilise le LLM Mistral-7B-Instruct, ces mêmes étapes peuvent être utilisées avec un LLM PyTorch de votre choix tel que Phi2, Llama2, etc. Et oui, avec le dernier modèle Llama3 aussi !
IPEX-LLM
La raison pour laquelle nous pouvons faire fonctionner une variété de modèles en utilisant la même installation de base est due à IPEX-LLMune bibliothèque LLM pour PyTorch. Elle est construite au dessus de Extension Intel® pour PyTorch et contient des optimisations LLM de pointe et une compression des poids à faible bit (INT4/FP4/INT8/FP8) - avec toutes les dernières optimisations de performance pour le matériel Intel. IPEX-LLM tire parti de la technologie Xe-XMX AI accélère les GPU discrets d'Intel, tels que les cartes graphiques de la série Arc A, pour améliorer les performances. Il prend en charge les cartes graphiques Intel Arc série A sur le sous-système Windows pour Linux version 2, les environnements Windows natifs et Linux natif.
Et comme tout ceci est du PyTorch natif, vous pouvez facilement échanger les modèles PyTorch et les données d'entrée pour les exécuter sur un GPU Intel Arc avec une accélération de haute performance. Cette expérience n'aurait pas été complète sans une comparaison des performances. En utilisant les instructions ci-dessous pour Intel Arc et les instructions couramment disponibles pour la concurrence, nous avons examiné deux GPU discrets positionnés dans un segment de prix similaire.
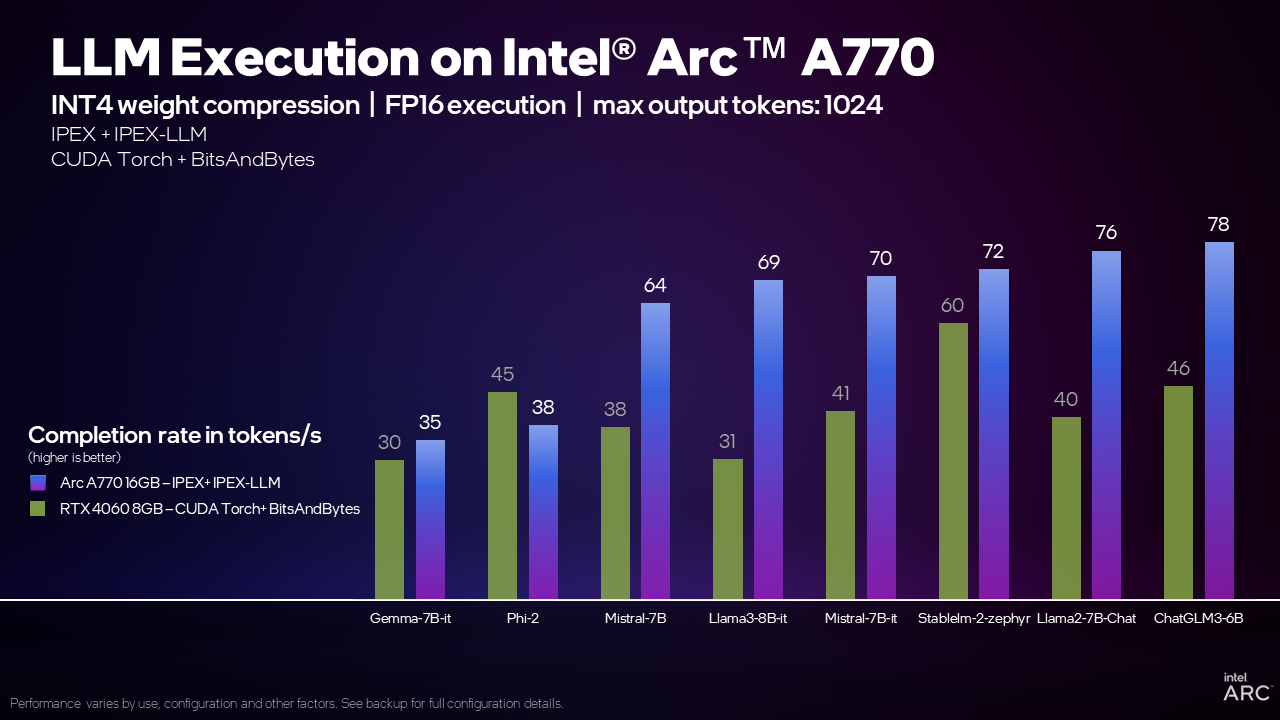
Par exemple, en exécutant le modèle Mistral 7B avec la bibliothèque IPEX-LLM, la carte graphique Arc A770 16 Go peut traiter 70 jetons par seconde (TPS), soit 70% TPS de plus que la GeForce RTX 4060 8 Go utilisant CUDA. Qu'est-ce que cela signifie ? En règle générale, un jeton équivaut à 0,75 mot. la vitesse de lecture humaine moyenne est de 4 mots par seconde ou 5,3 TPS. La carte graphique Arc A770 16GB peut générer des mots beaucoup plus rapidement que le commun des mortels ne peut les lire !
Nos tests internes montrent que la carte graphique Arc A770 16GB peut fournir cette capacité et des performances compétitives ou de pointe sur une large gamme de modèles par rapport à la RTX 4060, ce qui fait des cartes graphiques Intel Arc un excellent choix pour l'exécution locale de LLM.
Passons maintenant aux instructions de configuration pour vous permettre de commencer à utiliser les LLM sur votre GPU Arc A-series.
Instructions d'installation
Nous pouvons également nous référer à cette page pour la mise en place de l'environnement : Installer IPEX-LLM sur Windows avec un GPU Intel - Dernière documentation sur IPEX-LLM
1. Désactiver le GPU intégré dans le gestionnaire de périphériques.
2. Télécharger et installer Anaconda.
3. Une fois l'installation terminée, ouvrez le menu Démarrer, recherchez Anaconda Prompt, exécutez-le en tant qu'administrateur et créez un environnement virtuel à l'aide des commandes suivantes. Saisissez chaque commande séparément :
conda create -n llm python=3.10.6
conda activate llm
conda install libuv
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0 gradio
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
pip install transformers==4.38.04. Créez un document texte nommé demo.py et enregistrez-le dans C:\NUsers\NVotre_nom_d'utilisateur\NDocuments ou dans le répertoire de votre choix.
5. Ouvrez demo.py avec votre éditeur préféré et copiez-y l'exemple de code suivant :
from transformers import AutoTokenizer
from ipex_llm.transformers import AutoModelForCausalLM
import torch
import intel_extension_for_pytorch
device = "xpu" # le dispositif sur lequel charger le modèle
model_id = "mistralai/Mistral-7B-Instruct-v0.2" # identifiant du modèle de visage étreint
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, torch_dtype=torch.float16)
model = model.to(device)
messages = [
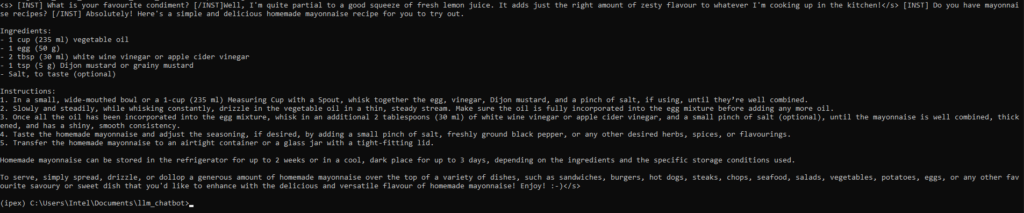
{"role" : "user", "content" : "Quel est votre condiment préféré ?"},
{"rôle" : "assistant", "content" : "Eh bien, j'aime bien presser du jus de citron frais. Il ajoute juste ce qu'il faut de saveur piquante à tout ce que je prépare dans la cuisine !"},
{"role" : "user", "content" : "Do you have mayonnaise recipes ?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])Code construit à partir de l'exemple de code dans ce dépôt.
6. Sauvegardez demo.py. Dans Anaconda, naviguez jusqu'au répertoire où se trouve demo.py en utilisant la commande cd, et exécutez la commande suivante dans l'invite d'Anaconda :
python demo.pyVous pouvez maintenant obtenir une bonne recette pour préparer la mayonnaise !
Changer de modèle
En utilisant le même environnement que nous avons mis en place ci-dessus, vous pouvez expérimenter d'autres modèles populaires sur Hugging Face tels que llama2-7B-chat-hf, llama3-8B-it, phi-2, gemma-7B-i, et stablelm2 en remplaçant le modèle Hugging Face id ci-dessus dans demo.py.
model_id = "mistralai/Mistral-7B-Instruct-v0.2" # huggingface model id
à
model_id = "stabilityai/stablelm-2-zephyr-1_6b" # huggingface model idSi vous rencontrez des erreurs lors du lancement de demo.py, suivez les étapes ci-dessous pour mettre à niveau ou rétrograder les transformateurs :
- Ouvrir l'invite Anaconda
- conda activer llm
- pip install transformers==4.37.0
Versions vérifiées des transformateurs :
| Modèle ID | Versions de l'emballage des transformateurs |
|---|---|
| meta-llama/Llama-2-7b-chat-hf | 4.37.0 |
| meta-llama/Meta-Llama-3-8B-Instruct | 4.37.0 |
| stabilitéai/stablelm-2-zephyr-1_6b | 4.38.0 |
| mistralai/Mistral-7B-Instruct-v0.2 | 4.38.0 |
| microsoft/phi-2 | 4.38.0 |
| google/gemma-7b-it | 4.38.1 |
| THUDM/chatglm3-6b | 4.38.0 |
Les besoins en mémoire peuvent varier selon le modèle et le cadre. Pour l'Intel Arc A750 8GB fonctionnant avec IPEX-LLM, nous recommandons d'utiliser Llama-2-7B-chat-hf, Mistral-7B-Instruct-v0.2, phi-2 ou chatglm3-6B.
Mise en œuvre d'une interface Web ChatBot
Passons maintenant à l'implémentation d'un chatbot Gradio webui pour une meilleure expérience en utilisant votre navigateur web. Pour plus d'informations sur la mise en œuvre d'un chatbot interactif avec les LLM, visitez le site suivant https://www.gradio.app/guides/creating-a-chatbot-fast
1. Créez un document nommé chatbot_gradio.py dans l'éditeur de texte de votre choix.
2. Copiez et collez l'extrait de code suivant dans chatbot_gradio.py :
Importation de gradio en tant que gr
import torch
import intel_extension_for_pytorch
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
model_id = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, optimize_model=True, load_in_4bit=True, torch_dtype=torch.float16)
modèle = modèle.half()
model = model.to("xpu")
classe StopOnTokens(StoppingCriteria) :
def __call__(self, input_ids : torch.LongTensor, scores : torch.FloatTensor, **kwargs) -> bool :
stop_ids = [29, 0]
pour stop_id dans stop_ids :
si input_ids[0][-1] == stop_id :
return True
retour Faux
def predict(message, history) :
stop = StopOnTokens()
history_format = []
pour human, assistant dans history :
history_format.append({"role" : "user", "content" : human })
history_format.append({"role" : "assistant", "content":assistant})
history_format.append({"role" : "user", "content" : message})
prompt = tokenizer.apply_chat_template(history_format, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to("xpu")
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=300,
do_sample=True,
top_p=0.95,
top_k=20,
température=0,8,
num_beams=1,
pad_token_id=tokenizer.eos_token_id,
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
partial_message = ""
pour new_token dans streamer :
if new_token != '<' :
partial_message += new_token
yield partial_message
gr.ChatInterface(predict).launch()3. Ouvrez une nouvelle invite anaconda et entrez les commandes suivantes :
- pip install gradio
- conda activer llm
- cd dans le répertoire où se trouve chat_gradio.py
- python chatbot_gradio.py
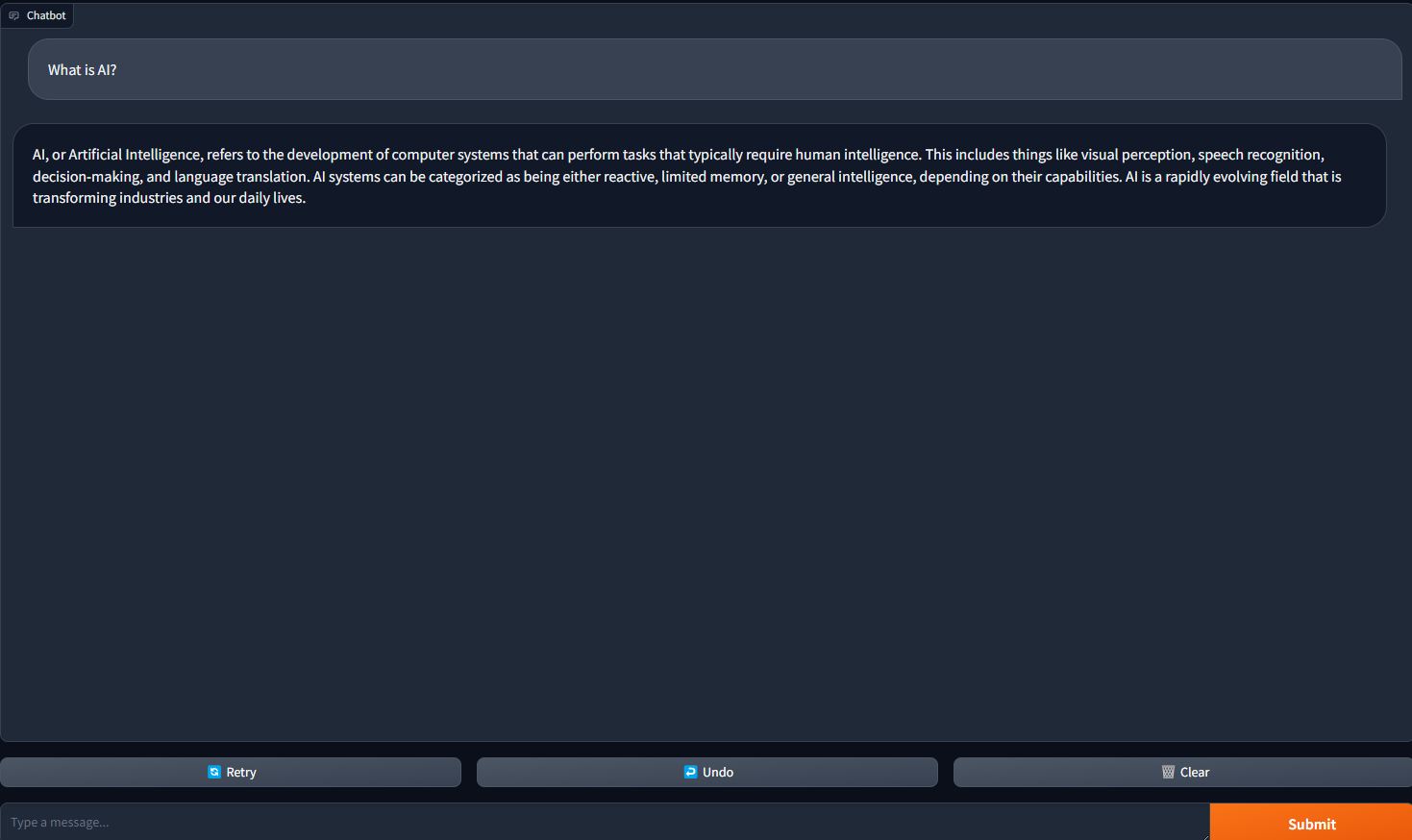
4. Ouvrez votre navigateur web et naviguez vers 127.0.0.1:7860. Vous devriez voir un chatbot configuré avec le modèle de langage mistral-7b-instruct-v0.2 ! Vous avez maintenant une interface web pour votre chatbot.
5. Posez une question pour entamer une conversation avec votre chatbot.
Remarques et avertissements
Les performances varient en fonction de l'utilisation, de la configuration et d'autres facteurs. Pour en savoir plus, consultez la page site Performance Index d'Intel.
Les résultats des performances sont basés sur des tests effectués aux dates indiquées dans les configurations et peuvent ne pas refléter toutes les mises à jour publiquement disponibles. Voir la sauvegarde pour les détails de la configuration. Aucun produit ou composant ne peut être absolument sûr.
Les résultats basés sur des systèmes et des composants de pré-production, ainsi que les résultats estimés ou simulés à l'aide d'une plate-forme de référence Intel (un exemple interne de nouveau système), d'une analyse interne Intel ou d'une simulation ou modélisation d'architecture, vous sont fournis à titre d'information uniquement. Les résultats peuvent varier en fonction des changements futurs apportés aux systèmes, composants, spécifications ou configurations.
Vos coûts et résultats peuvent varier.
Les technologies Intel peuvent être soumises au recours à des logiciels, des services ou des matériels particuliers.
Intel Corporation. Intel, le logo Intel, Arc et les autres marques Intel sont des marques commerciales d'Intel Corporation ou de ses filiales.
*Les autres marques et noms de marque peuvent être réclamés comme propriétés d'autres parties.