インテル® Arc™ GPUを使用して、さまざまなLLMをローカルで簡単に実行可能
ジェネレーティブAIは、コンテンツ制作の可能性を大きく変えた。このテクノロジーは、これまで想像もできなかった画像、動画、文章を提供する可能性を秘めている。大規模な言語モデル(LLM)はAIの時代に大きな話題を呼んでおり、誰でも歌の歌詞を生成したり、複雑な物理学の質問に対する答えを得たり、スライド・プレゼンテーションのアウトラインを起草したりする方法を促すことができる。そしてこれらのAI機能は、もはやクラウドやサブスクリプション・サービスに接続する必要はない。自分のPC上でローカルに動作させることができ、モデルを完全に制御して出力をカスタマイズすることができる。
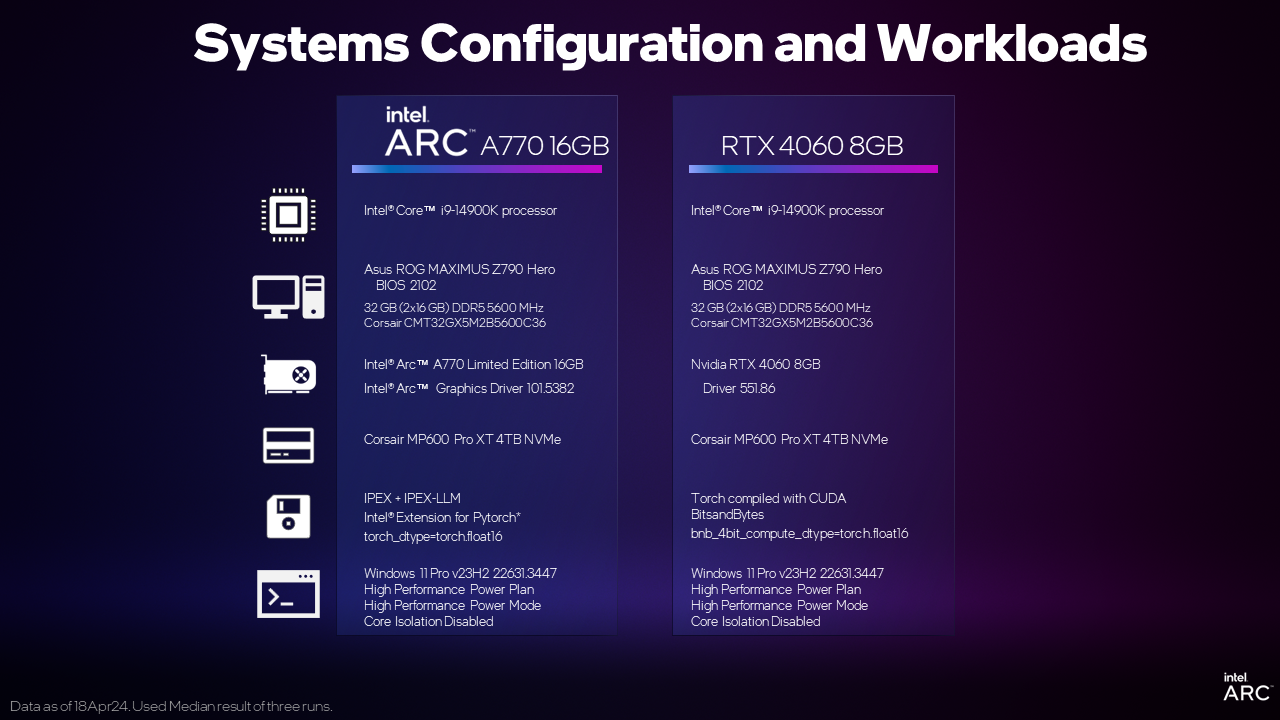
この記事では、Intel® Arc™ A770 16GBグラフィックスカードを搭載したPCで、一般的な大規模言語モデル(LLM)をセットアップして実験する方法を紹介します。このチュートリアルではMistral-7B-Instruct LLMを使用しますが、Phi2やLlama2などお好みのPyTorch LLMでも同じ手順で使用できます。もちろん、最新のLlama3モデルでも使えます!
IPEX-LLM
同じベース・インストレーションを使ってさまざまなモデルを走らせることができるのは、次のような理由からだ。 IPEX-LLMPyTorch 用の LLM ライブラリです。これは PyTorch 用インテル® エクステンション IPEX-LLMは、最新のLLM最適化とロービット(INT4/FP4/INT8/FP8)重み圧縮を含み、Intelハードウェアのためのすべての最新のパフォーマンス最適化を備えています。IPEX-LLMはXe-Arc AシリーズグラフィックスカードのようなIntelディスクリートGPU上でXMX AIアクセラレーションをコアとし、パフォーマンスを向上。Windows Subsystem for Linuxバージョン2、ネイティブWindows環境、ネイティブLinux上でIntel Arc Aシリーズグラフィックスをサポートします。
また、これらはすべてネイティブのPyTorchなので、PyTorchモデルと入力データを簡単に入れ替えて、高性能アクセラレーションを備えたインテルArc GPU上で実行することができる。この実験は、性能比較なしには完了しませんでした。以下のIntel Arc用のインストラクションと、競合製品用の一般的に入手可能なインストラクションを使用して、同じような価格セグメントに位置する2つのディスクリートGPUを見てみました。
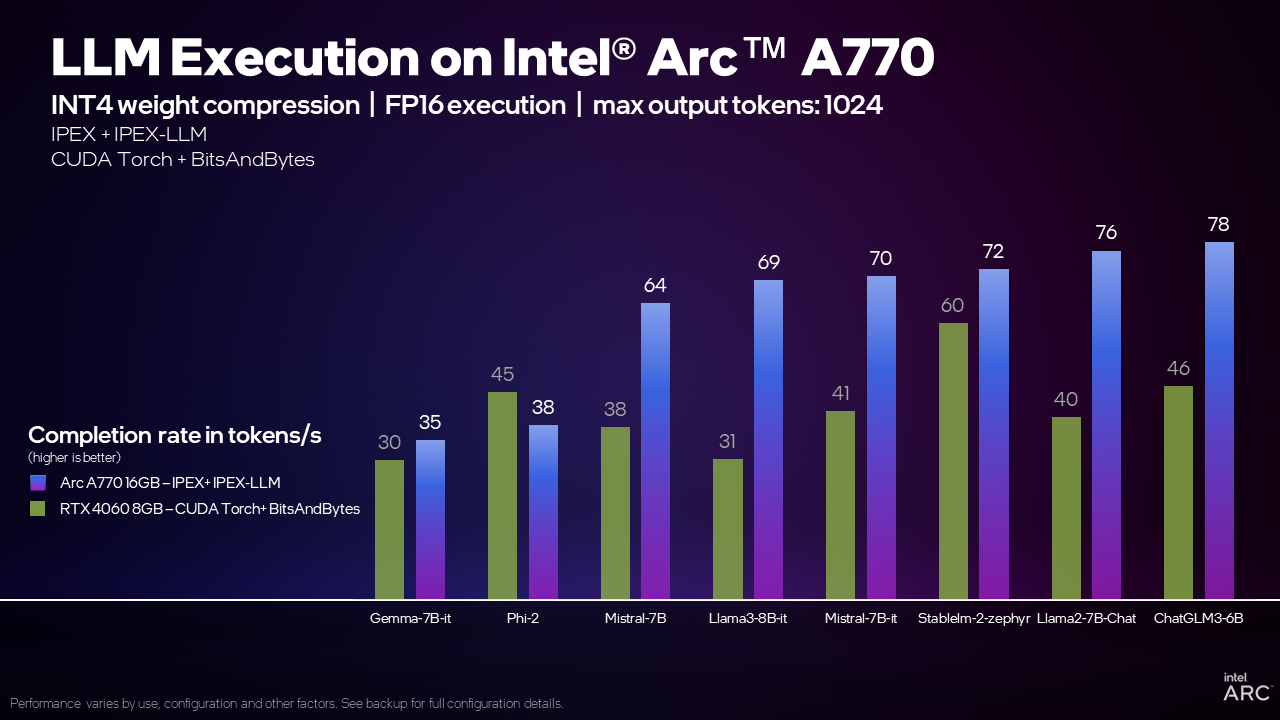
例えば、IPEX-LLMライブラリを使用してMistral 7Bモデルを実行する場合、Arc A770 16GBグラフィックカードは、CUDAを使用してGeForce RTX 4060 8GBよりも毎秒70トークン(TPS)、つまり70%多いTPSを処理することができます。これは何を意味するのでしょうか?一般的な経験則では、1トークンは1単語の0.75に相当し、良い比較対象は 人間の平均読書速度は1秒間に4語 または5.3 TPSです。Arc A770 16GBグラフィックカードは、一般人が文字を読むよりもはるかに速く文字を生成することができる!
当社の内部テストによると、Arc A770 16GBグラフィックスカードは、RTX 4060と比較して、幅広いモデルでこの能力を発揮し、競争力のある、あるいはトップクラスの性能を発揮できることが分かっており、Intel Arcグラフィックスは、ローカルLLM実行に最適な選択肢となっています。
それでは、Arc AシリーズGPUでLLMを始めるためのセットアップ手順を説明します。
インストレーション・インストラクション
環境構築については、こちらのページも参考にしてほしい: インテルGPUを搭載したWindowsにIPEX-LLMをインストールする - IPEX-LLM最新ドキュメント
1.デバイスマネージャで統合GPUを無効にする。
2.ダウンロードとインストール アナコンダ.
3.インストールが完了したら、スタートメニューを開き、Anaconda Prompt を検索し、管理者として実行し、以下のコマンドを使用して仮想環境を作成します。各コマンドは別々に入力します:
conda create -n llm python=3.10.6
llm を起動する
libuv をインストールする
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0 gradio
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
pip install transformers==4.38.04.4.demo.pyという名前のテキストドキュメントを作成し、C:⇄UsersYour_Username⇄Documentsまたは任意のディレクトリに保存します。
5.好きなエディタでdemo.pyを開き、以下のコードサンプルをコピーしてください:
from transformers import AutoTokenizer
from ipex_llm.transformers import AutoModelForCausalLM
インポートトーチ
インポート intel_extension_for_pytorch
device = "xpu" #モデルをロードするデバイス。
model_id = "mistralai/Mistral-7B-Instruct-v0.2" #抱きつき顔のモデルID
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, torch_dtype=torch.float16)
model = model.to(デバイス)
メッセージ = [
{"role":"user", "content":「好きな調味料は何ですか?}
{"role":"assistant", "content":"まあ、私は新鮮なレモン汁をよく絞るのが好きですね。キッチンでどんな料理を作るときでも、ピリッとした風味をプラスしてくれるんです!"}、
{"role":"user", "content":「マヨネーズのレシピはありますか?}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(デバイス)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
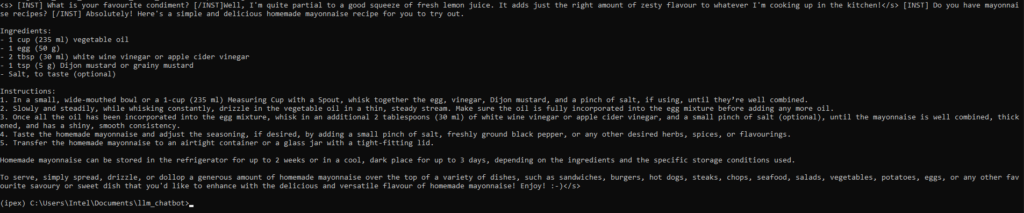
print(decoded[0])サンプルコードからビルドしたコード このリポジトリ.
6.demo.py を保存します。Anaconda で、cd コマンドを使って demo.py があるディレクトリに移動し、Anaconda プロンプトで以下のコマンドを実行します:
python demo.pyマヨネーズ作りの素敵なレシピが手に入る!
モデルチェンジ
上で設定したのと同じ環境を使い、demo.pyでハギング・フェイスのモデルidを置き換えることで、llama2-7B-chat-hf, llama3-8B-it, phi-2, gemma-7B-i, stablelm2 など、ハギング・フェイスで人気のある他のモデルを試すことができます。
model_id = "mistralai/Mistral-7B-Instruct-v0.2" #ハギングフェイスのモデルID
に
model_id = "stabilityai/stablelm-2-zephyr-1_6b" # huggingface モデルIDもし demo.py の起動時にエラーが発生した場合は、以下の手順で transformers をアップグレード/ダウングレードしてください:
- アナコンダプロンプトを開く
- コンダ・アクティベートllm
- pip install transformers==4.37.0
トランスフォーマーのバージョンを確認:
| モデルID | トランスフォーマー パッケージ版 |
|---|---|
| メタラマ/ラマ2-7b-チャット-hf | 4.37.0 |
| メタラマ/メタラマ-3-8B-インストラクト | 4.37.0 |
| 安定ai/安定lm-2-ゼファー-1_6b | 4.38.0 |
| mistralai/Mistral-7B-Instruct-v0.2 | 4.38.0 |
| マイクロソフト/ファイ2 | 4.38.0 |
| google/gemma-7b-it | 4.38.1 |
| THUDM/chatglm3-6b | 4.38.0 |
メモリ要件はモデルやフレームワークによって異なる場合があります。IPEX-LLM で動作する Intel Arc A750 8GB では、Llama-2-7B-chat-hf, Mistral-7B-Instruct-v0.2, phi-2 または chatglm3-6B の使用をお勧めします。
ChatBot WebUIの実装
それでは、Gradioチャットボットのウェブイを実装して、ウェブブラウザを使ってより良い体験を提供しましょう。LLMとの対話型チャットボットの実装に関する詳細は、以下をご覧ください。 https://www.gradio.app/guides/creating-a-chatbot-fast
1.好きなテキストエディタで chatbot_gradio.py という名前のドキュメントを作成します。
2.以下のコードスニペットをコピーしてchatbot_gradio.pyに貼り付けます:
gradioをgrとしてインポートする
インポートトーチ
インポート intel_extension_for_pytorch
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
model_id = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, optimize_model=True, load_in_4bit=True, torch_dtype=torch.float16)
model = model.half()
model = model.to("xpu")
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [29, 0]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
偽を返す
def predict(message, history):
stop = StopOnTokens()
history_format = [].
for human, assistant in history:
history_format.append({"role": "user", "content": human })
history_format.append({"role": "assistant", "content":assistant})
history_format.append({"role": "user", "content": メッセージ})
prompt = tokenizer.apply_chat_template(history_format, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to("xpu")
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs、
streamer=streamer、
max_new_tokens=300、
do_sample=True、
top_p=0.95、
top_k=20、
temperature=0.8、
num_beams=1、
pad_token_id=tokenizer.eos_token_id、
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
partial_message = ""
for new_token in streamer:
if new_token != '<':
partial_message += new_token
yield partial_message
gr.ChatInterface(predict).launch()3.新しい anaconda プロンプトを開き、以下のコマンドを入力する:
- pip install gradio
- コンダ・アクティベートllm
- chat_gradio.pyがあるディレクトリにcdする。
- python chatbot_gradio.py
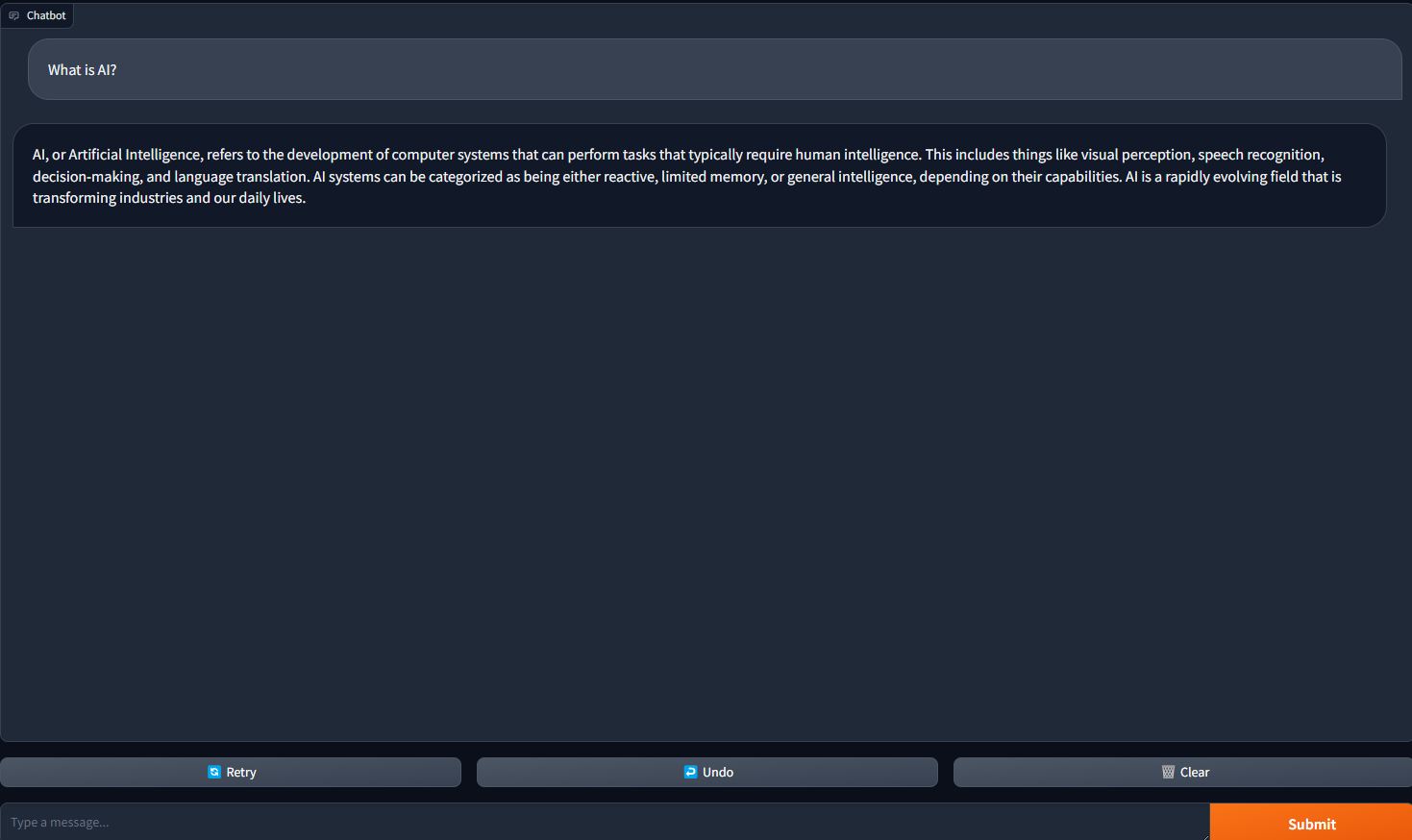
4.ウェブブラウザを開き、127.0.0.1:7860に移動します。mistral-7b-instruct-v0.2言語モデルでセットアップされたチャットボットが表示されるはずです!これで、チャットボット用のおしゃれなWebUIができました。
5.チャットボットとの会話を始めるために質問をします。
通知および免責事項
性能は用途や構成、その他の要因によって異なります。詳しくは パフォーマンス・インデックス・サイト.
パフォーマンス結果は、コンフィギュレーションに記載されている日付時点でのテストに基づくものであり、一般に公開されているすべてのアップデートが反映されているわけではありません。構成の詳細については、バックアップをご覧ください。絶対的に安全な製品やコンポーネントはありません。
量産前のシステムおよびコンポーネントに基づく結果、インテル・リファレンス・プラットフォーム (社内の新システム例)、インテル社内の分析、アーキテクチャーのシミュレーションまたはモデリングを使用して推定またはシミュレートされた結果は、情報提供のみを目的としています。将来のシステム、コンポーネント、仕様、構成の変更により、結果が異なる場合があります。
あなたの費用と結果は異なるかもしれない。
インテルのテクノロジーには、ハードウェア、ソフトウェア、またはサービスのアクティベーションが必要な場合があります。
© Intel Corporation.Intel、Intel ロゴ、Arc、およびその他の Intel マークは、Intel Corporation またはその子会社の商標です。
*その他の名称やブランドは、他者の所有物であると主張される場合があります。