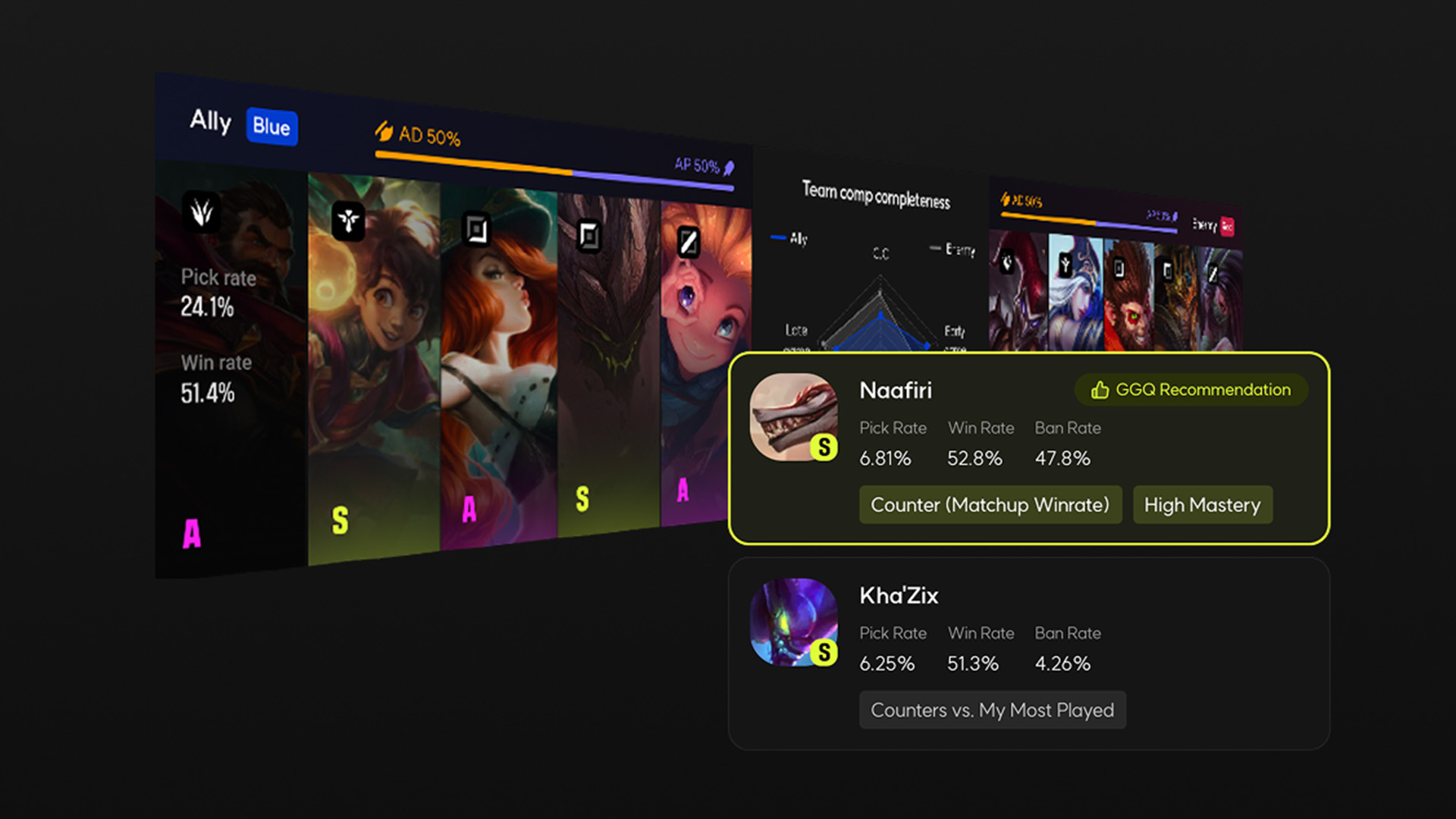
FragPunk, the 5v5 hero shooter with Shard Cards (powerful gameplay modifiers that break the rules) launches on Steam and Epic Games Store for free on March 6th (Pacific Time), with 150+ Shard Cards, 10+ rotating game modes, and loads of free cosmetics!
Back in October 2024, we invited Bad Guitar Studio, makers of FragPunk, to Intel Gaming Access to tell us about their FPS with attitude. To give you the quick version of our chat here, FragPunk is a self-declared “punk” FPS with a card system at its core that changes the rules of engagement each round. It’s a super-stylish, lightning-fast blast of a shooter, with more than its fair share of silly but still effective gameplay chaos to keep its players entertained. How it works is, prior to each round, teams draw three cards which throw a variety of curveballs at the ensuing combat, ranging from super healing and wild weaponry, to a more outlandish type of fun such as over-inflated enemy heads and a turtle that protects your back from rear fire. Used this way, every card is a wild card. Gamers embraced the game’s punk-rock spirit at Closed Beta stage, and now we are psyched to tell you that the full game is about to launch like a punk rocker into a mosh pit. Get ready to break some rules, and have some fun.
New Cards Flipping!
For the full launch, Bad Guitar are going full punk. They’ve added new cards for you to use to break more rules. The card pool now extends to 150+ cards (up from around 110), which makes things pleasingly anarchic for those who are already loving the game’s punk edge. It’s worth saying, however, that the cards disrupt, they don’t destroy—in terms of game momentum. Using one, you won’t screech to a halt, just start a new riff. Bombs called converters get planted—players might need to defuse one. If it’s too dangerous to get close, you can use the “Psychic Defusing” card to make the bomb defuse itself. If you want that bomb to not only stay put but to be right on target, use the “Throw to Plant” for automatic planting. “Tick Tock” disables all target sites one minute after the game starts. Predictable gameplay? Nah. With FragPunk, you—and more importantly the enemy—won’t see it coming; it’s all in the cards.
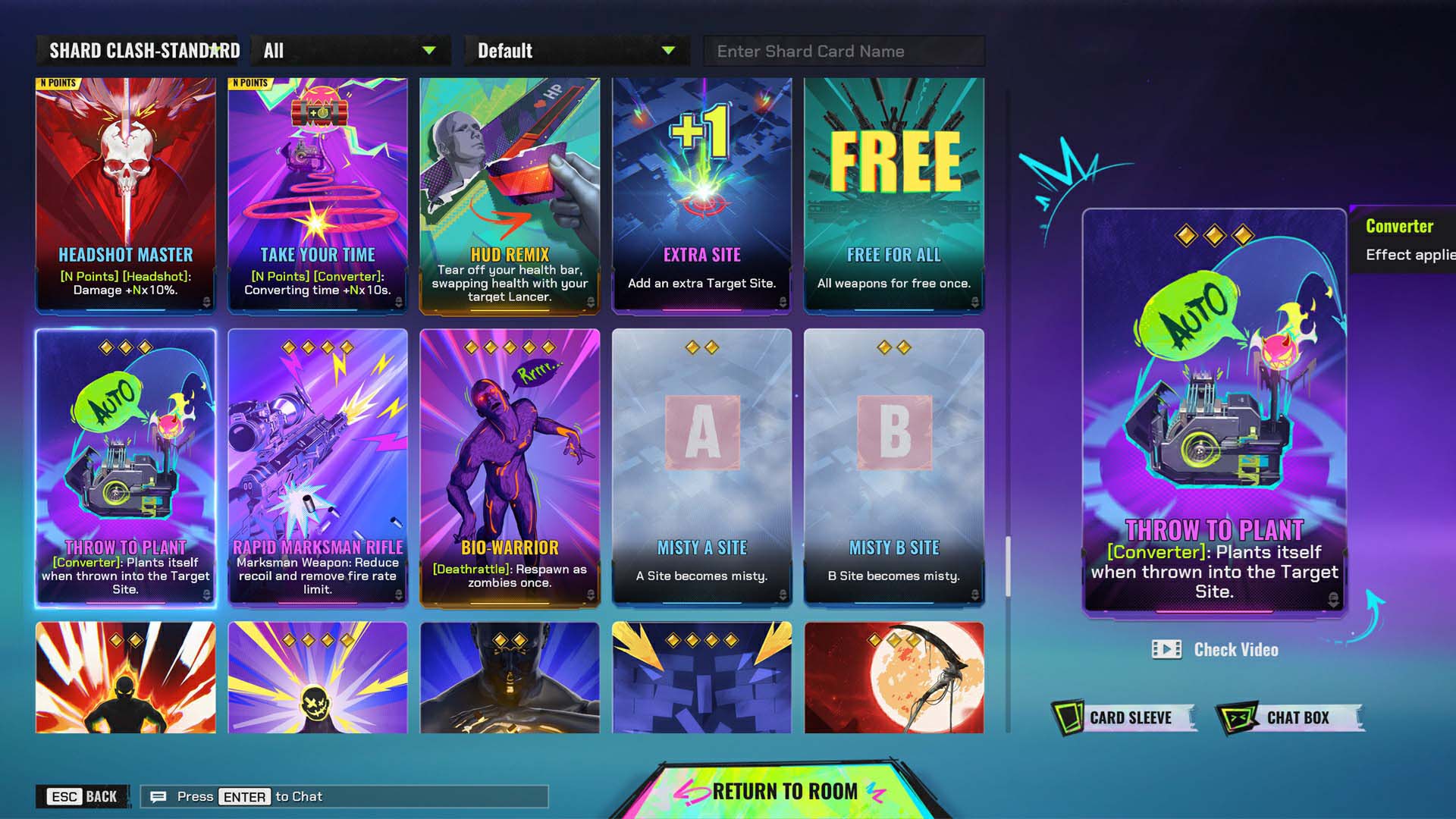
Loads of New Modes
Planting converters is a ton of fun, but if you want to take a break from that kind of life, or even from playing as a living human, check out Zombie Mode. You can be a defender of humanity and try to stop as many people as possible from being turned, or, if you happen to get infected, you can add to the zombie hordes by trying to infect as many humans as you can.

Team Death Match, Single Weapon Player
What weapon works for you? Sword, long-range sniper rifle, pistol? A single weapon doesn’t mean a lack of choice. The new variations of Team Death Match (TDM) modes allow you to use one weapon, but rotate regularly. As Bad Guitar put it to us: “Show ’em your mastery of your favourite weapons!” And we will, but you can also test your handiness with a variety of weapons because of the rotation, so you develop specific skills without getting locked in.

New Skins, a Longer Lasting Pass
Bad Guitar were keen to tell us about a little launch gift for all the proto-punks out there. “We have prepared a brand new Azure Blossom skin for all playable weapons at launch, which can all be obtained for free by participating in our events!”

Getting great stuff for free is very punk, and Bad Guitar deliver. Check out the Battle Pass for something unexpected. “Unlike what you have seen in other games,” Bad Guitar says, “FragPunk‘s Battle Pass will have NO expiration [from] the very first season! You will still be able to complete the battle pass and receive rewards after a season ends.”
Unlock FragPunk on Steam